leetcode探索之二叉树学习 总结
作者:whisper
链接:http://proprogrammar.com:443/article/618
声明:请尊重原作者的劳动,如需转载请注明出处
在完成前面的章节之后,你应该能够熟悉二叉树以及具备解决相关问题的能力。
在本章节中,我们会为你提供更多练习,帮助你以后在解决树的问题中更加自信!
算法-从中序与后序遍历序列构造二叉树
根据一棵树的中序遍历与后序遍历构造二叉树。
注意:
你可以假设树中没有重复的元素。例如,给出
中序遍历 inorder = [9,3,15,20,7] 后序遍历 postorder = [9,15,7,20,3]返回如下的二叉树:
3 / \ 9 20 / \ 15 7
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
// 想法:部分和整体符合同一规则,想到用分治递归
public TreeNode buildTree(int[] inorder, int[] postorder) {
Map<Integer, Integer> map = new HashMap<>();
for(int i = 0; i < inorder.length; i++){
map.put(inorder[i], i);
}
return buildTree(inorder, 0, inorder.length - 1, postorder, 0, postorder.length - 1, map);
}
private TreeNode buildTree(int[] inorder, int inStart, int inEnd, int[] postorder, int postStart, int postEnd, Map<Integer, Integer> map){
TreeNode node = null;
int i = -1;
if(postEnd - postStart == 0){
node = new TreeNode(postorder[postEnd]);
}else if(postEnd - postStart > 0){
i = map.get(postorder[postEnd]);
node = new TreeNode(postorder[postEnd]);
node.left = buildTree(inorder, inStart, i - 1, postorder, postStart, postStart + i - 1 - inStart, map);
node.right = buildTree(inorder, i + 1, inEnd, postorder, postEnd - inEnd + i, postEnd - 1, map);
}
return node;
}
}用了一个辅助map,用后序序列来解题,利用了左右子树在序列中是连续在一起的,看一种效率较高的
class Solution {
int inIndex;
int postIndex;
public TreeNode buildTree(int[] inorder, int[] postorder) {
inIndex=inorder.length-1;
postIndex=postorder.length-1;
return helper(inorder,postorder,(long)Integer.MAX_VALUE+1);
}
public TreeNode helper(int[] inorder, int[] postorder, long stop){
if(postIndex<0){
return null;
}
if(inorder[inIndex]==stop){
inIndex--;
return null;
}
int val=postorder[postIndex--];
TreeNode root=new TreeNode(val);
root.right=helper(inorder,postorder,val);
root.left=helper(inorder,postorder,stop);
return root;
}
}这个代码看不太懂,想不太明白,用了一个stop标记,是一种自顶向下的分治的解法,而stop的判断是自底向上的,有点慒。。。先放在这里吧
算法-从前序与中序遍历序列构造二叉树
根据一棵树的前序遍历与中序遍历构造二叉树。
注意:
你可以假设树中没有重复的元素。例如,给出
前序遍历 preorder = [3,9,20,15,7] 中序遍历 inorder = [9,3,15,20,7]返回如下的二叉树:
3 / \ 9 20 / \ 15 7
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
// 想法:类似中序与后序
public TreeNode buildTree(int[] preorder, int[] inorder) {
Map<Integer, Integer> map = new HashMap<>();
for(int i = 0; i < inorder.length; i++){
map.put(inorder[i], i);
}
return buildTree(preorder, 0, preorder.length - 1, inorder, 0, inorder.length - 1, map);
}
private TreeNode buildTree(int[] preorder, int preStart, int preEnd, int[] inorder, int inStart, int inEnd, Map<Integer, Integer> map){
TreeNode node = null;
int i = -1;
if(preEnd - preStart == 0){
node = new TreeNode(preorder[preStart]);
}else if(preEnd - preStart > 0){
i = map.get(preorder[preStart]);
node = new TreeNode(preorder[preStart]);
node.left = buildTree(preorder, preStart + 1, preStart + i - inStart, inorder, inStart, i - 1, map);
node.right = buildTree(preorder, preEnd - inEnd + i + 1, preEnd, inorder, i + 1, inEnd, map);
}
return node;
}
}类似上一题的中序与后序,再看另一种效率较高的
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode buildTree(int[] preorder, int[] inorder) {
return buildTreeHelper(preorder, inorder, (long)Integer.MAX_VALUE + 1);
}
int pre = 0;
int in = 0;
private TreeNode buildTreeHelper(int[] preorder, int[] inorder, long stop) {
//到达末尾返回 null
if(pre == preorder.length){
return null;
}
//到达停止点返回 null
//当前停止点已经用了,in 后移
if (inorder[in] == stop) {
in++;
return null;
}
int root_val = preorder[pre++];
TreeNode root = new TreeNode(root_val);
//左子树的停止点是当前的根节点
root.left = buildTreeHelper(preorder, inorder, root_val);
//右子树的停止点是当前树的停止点
root.right = buildTreeHelper(preorder, inorder, stop);
return root;
}
}这个解法也类似上一题的第二种解法,看不太明白,先放这里吧
解法-填充每个节点的下一个右侧节点指针
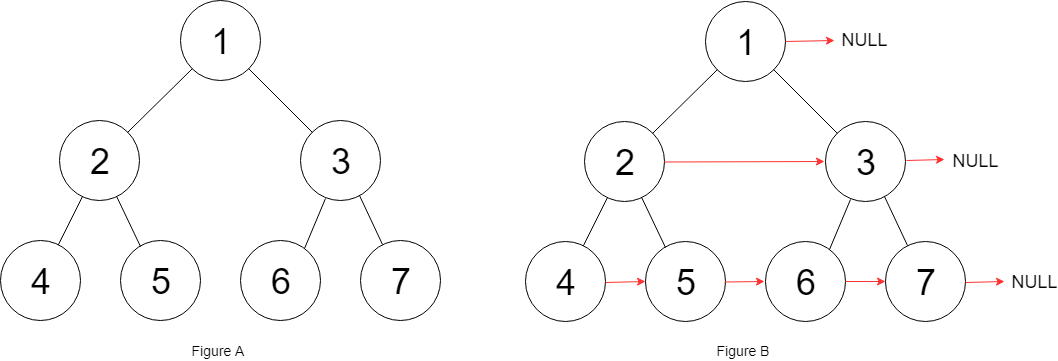
给定一个完美二叉树,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
struct Node { int val; Node *left; Node *right; Node *next; }填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
示例:
输入:{"$id":"1","left":{"$id":"2","left":{"$id":"3","left":null,"next":null,"right":null,"val":4},"next":null,"right":{"$id":"4","left":null,"next":null,"right":null,"val":5},"val":2},"next":null,"right":{"$id":"5","left":{"$id":"6","left":null,"next":null,"right":null,"val":6},"next":null,"right":{"$id":"7","left":null,"next":null,"right":null,"val":7},"val":3},"val":1} 输出:{"$id":"1","left":{"$id":"2","left":{"$id":"3","left":null,"next":{"$id":"4","left":null,"next":{"$id":"5","left":null,"next":{"$id":"6","left":null,"next":null,"right":null,"val":7},"right":null,"val":6},"right":null,"val":5},"right":null,"val":4},"next":{"$id":"7","left":{"$ref":"5"},"next":null,"right":{"$ref":"6"},"val":3},"right":{"$ref":"4"},"val":2},"next":null,"right":{"$ref":"7"},"val":1} 解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。提示:
- 你只能使用常量级额外空间。
- 使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。
/*
// Definition for a Node.
class Node {
public int val;
public Node left;
public Node right;
public Node next;
public Node() {}
public Node(int _val,Node _left,Node _right,Node _next) {
val = _val;
left = _left;
right = _right;
next = _next;
}
};
*/
class Solution {
// 想法:广度优先层次遍历,用两个集合存当前层与下一层
public Node connect(Node root) {
Queue<Node> cur = new LinkedList<>(), next;
Node curNode;
if(root == null){
return null;
}
cur.offer(root);
while(!cur.isEmpty()){
curNode = cur.poll();
next = new LinkedList<>();
if(curNode.left != null){
next.offer(curNode.left);
}
if(curNode.right != null){
next.offer(curNode.right);
}
while(!cur.isEmpty()){
curNode.next = cur.peek();
curNode = cur.poll();
if(curNode.left != null){
next.offer(curNode.left);
}
if(curNode.right != null){
next.offer(curNode.right);
}
}
cur = next;
}
return root;
}
}用队列广度优先获取每一层,再处理每一层,写这个时候还比较差劲,用了两个队列,其实一个就可以了,下面看另一种比较好的解法
/*
// Definition for a Node.
class Node {
public int val;
public Node left;
public Node right;
public Node next;
public Node() {}
public Node(int _val) {
val = _val;
}
public Node(int _val, Node _left, Node _right, Node _next) {
val = _val;
left = _left;
right = _right;
next = _next;
}
};
*/
class Solution {
public Node connect(Node root) {
if(root == null) return null;
if(root.left == null) return root;
root.left.next = root.right;
if(root.next!=null)root.right.next = root.next.left;
connect(root.left);
connect(root.right);
return root;
}
}很简洁的解法,核心就是每一次当前节点处理下一层的两个子节点
算法-填充每个节点的下一个右侧节点指针 II
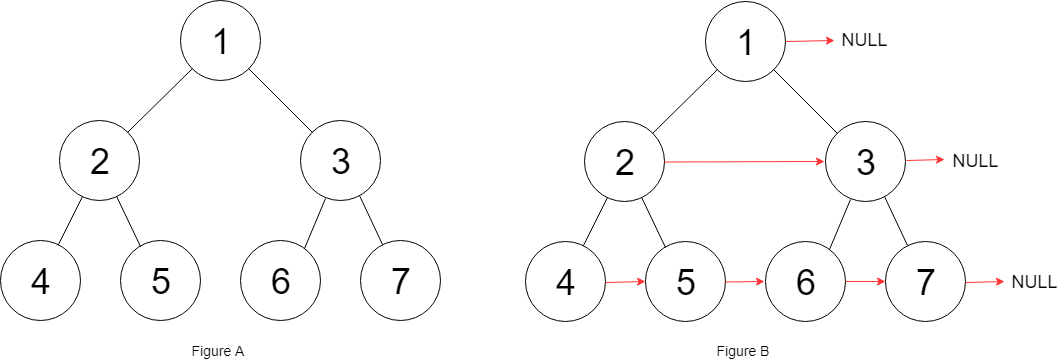
给定一个二叉树
struct Node { int val; Node *left; Node *right; Node *next; }填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
进阶:
- 你只能使用常量级额外空间。
- 使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。
示例:
输入:root = [1,2,3,4,5,null,7] 输出:[1,#,2,3,#,4,5,7,#] 解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。提示:
- 树中的节点数小于 6000
- -100 <= node.val <= 100
/*
// Definition for a Node.
class Node {
public int val;
public Node left;
public Node right;
public Node next;
public Node() {}
public Node(int _val,Node _left,Node _right,Node _next) {
val = _val;
left = _left;
right = _right;
next = _next;
}
};
*/
class Solution {
public Node connect(Node root) {
Queue<Node> cur = new LinkedList<>(), next;
Node curNode;
if(root == null){
return null;
}
cur.offer(root);
while(!cur.isEmpty()){
curNode = cur.poll();
next = new LinkedList<>();
if(curNode.left != null){
next.offer(curNode.left);
}
if(curNode.right != null){
next.offer(curNode.right);
}
while(!cur.isEmpty()){
curNode.next = cur.peek();
curNode = cur.poll();
if(curNode.left != null){
next.offer(curNode.left);
}
if(curNode.right != null){
next.offer(curNode.right);
}
}
cur = next;
}
return root;
}
}类似上一题,我还是用了两个栈,看另一种比较好的解法
/*
// Definition for a Node.
class Node {
public int val;
public Node left;
public Node right;
public Node next;
public Node() {}
public Node(int _val) {
val = _val;
}
public Node(int _val, Node _left, Node _right, Node _next) {
val = _val;
left = _left;
right = _right;
next = _next;
}
};
*/
class Solution {
public Node connect(Node root) {
Node curr = root;
Node head = new Node(-1);
Node node = head;
while(curr != null){
Node temp = curr;
while(temp != null){
if(temp.left != null){
node.next = temp.left;
node = node.next;
}
if(temp.right != null){
node.next = temp.right;
node = node.next;
}
temp = temp.next;
}
curr = head.next;
head.next = null;
node = head;
}
return root;
}
}核心还是类似上一题,用上一层节点处理下一层,技巧是每一层的next节点形成一个链表来处理
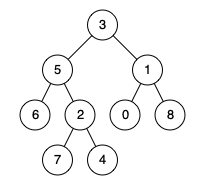
算法-二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
示例 1:
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 输出: 3 解释: 节点 5 和节点 1 的最近公共祖先是节点 3。示例 2:
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 输出: 5 解释: 节点 5 和节点 4 的最近公共祖先是节点 5。因为根据定义最近公共祖先节点可以为节点本身。说明:
- 所有节点的值都是唯一的。
- p、q 为不同节点且均存在于给定的二叉树中。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
// 想法:找出所有祖先,例如有n个,因为根结点一定是祖先,每一层都有一个祖先,向下找n层,第n层的祖先就是最近公共祖先
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
List<TreeNode> ancestors = new ArrayList<>();
commonAncestor(root, p, q, ancestors);
TreeNode temp = root, left, right;
for(int i = 0; i < ancestors.size() - 1; i++){
if(temp.left != null && ancestors.contains(temp.left)){
temp = temp.left;
continue;
}
if(temp.right != null && ancestors.contains(temp.right)){
temp = temp.right;
continue;
}
}
return temp;
}
private boolean isAncestor(TreeNode ancestor, TreeNode node){
if(ancestor.val == node.val){
return true;
}else{
if(ancestor.left != null && ancestor.right != null){
return isAncestor(ancestor.left, node) || isAncestor(ancestor.right, node);
}else if(ancestor.left != null){
return isAncestor(ancestor.left, node);
}else if(ancestor.right != null){
return isAncestor(ancestor.right, node);
}
}
return false;
}
private void commonAncestor(TreeNode node, TreeNode p, TreeNode q, List<TreeNode> ancestors){
if(isAncestor(node, p) && isAncestor(node, q)){
ancestors.add(node);
if(node.left != null){
commonAncestor(node.left, p, q, ancestors);
}
if(node.right != null){
commonAncestor(node.right, p, q, ancestors);
}
}
}
}自己写的渣代码,先找出所有公共祖先,再找公共祖先中最近的,看一种比较好的解法
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
private TreeNode target = null; // 记录结果
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
/**
* 思路:分三种情况:
* 1. 一个节点的左右子树都找到值,那么该节点就是公共祖先
* 2. 左子树找到值,当前值等于另一个,那么当前值就是公共祖先
* 3。右子树找到值,当前值等于另一个,那么当前值就是公共祖先
* 定义三个变量分别代表左右子树和当前值的情况,与上面三种情况做对比
*/
recurseTree(root, p, q);
return target;
}
private boolean recurseTree(TreeNode root, TreeNode p, TreeNode q) {
if(target != null){
return false;
}
boolean left = false, right = false, mid = false;
if (root != null) {
mid = root.val == p.val || root.val == q.val; // 当前值
left = recurseTree(root.left, p, q); // 递归左子树
if(mid && left){
this.target = root;
}else{
right = recurseTree(root.right, p, q); // 递归右子树
if ((mid && right) || (left && right)) { // 找到目标结果的情况
this.target = root;
}
}
}
// 范围本次递归结果
return mid || right || left;
}
}思路在注释里, 优化在于找到target后提前结束递归
算法-二叉树的序列化与反序列化
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
示例:
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。 请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。 示例:提示: 这与 LeetCode 目前使用的方式一致,详情请参阅 LeetCode 序列化二叉树的格式。你并非必须采取这种方式,你也可以采用其他的方法解决这个问题。
说明: 不要使用类的成员 / 全局 / 静态变量来存储状态,你的序列化和反序列化算法应该是无状态的。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
// 想法:按层存val,下层处理的数量应为上层数量的2倍(包括null),下层不包括null
public class Codec {
// Encodes a tree to a single string.
public String serialize(TreeNode root) {
Queue<TreeNode> queue = new LinkedList<>();
TreeNode temp;
StringBuilder sb = new StringBuilder();
if(root == null) {
return "";
}
queue.offer(root);
sb.append(root.val).append(",");
while(!queue.isEmpty()){
temp = queue.poll();
if(temp.left != null){
queue.offer(temp.left);
sb.append(temp.left.val).append(",");
}else{
sb.append(Integer.MAX_VALUE).append(",");
}
if(temp.right != null){
queue.offer(temp.right);
sb.append(temp.right.val).append(",");
}else{
sb.append(Integer.MAX_VALUE).append(",");
}
}
sb.setLength(sb.length() - 1);
return sb.toString();
}
// Decodes your encoded data to tree.
public TreeNode deserialize(String data) {
if(data == null || data.length() == 0) {
return null;
}
String[] vals = data.split(",");
Queue<TreeNode> cur = new LinkedList<>(), next;
TreeNode tempNode, newNode;
int val1, val2, index = 1, tempIndex;
TreeNode root = new TreeNode(Integer.parseInt(vals[0]));
cur.offer(root);
while(!cur.isEmpty()){
next = new LinkedList<>();
while(!cur.isEmpty()){
tempNode = cur.poll();
val1 = Integer.parseInt(vals[index++]);
val2 = Integer.parseInt(vals[index++]);
if(val1 == Integer.MAX_VALUE){
tempNode.left = null;
}else{
newNode = new TreeNode(val1);
tempNode.left = newNode;
next.offer(newNode);
}
if(val2 == Integer.MAX_VALUE){
tempNode.right = null;
}else{
newNode = new TreeNode(val2);
tempNode.right = newNode;
next.offer(newNode);
}
}
cur = next;
}
return root;
}
}
// Your Codec object will be instantiated and called as such:
// Codec codec = new Codec();
// codec.deserialize(codec.serialize(root));利用队列一层层序列化与反序列化结点,技巧在于如果一个结点存在,那么无论左右结点是否存在都要保存信息,这里是利用广度来做的,下面看一种利用深度来做的解法
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
public class Codec {
public String serialize(TreeNode root) {
StringBuilder sb = new StringBuilder();
dfs(root, sb);
return sb.toString();
}
private void dfs(TreeNode root, StringBuilder sb) {
if (root == null) {
sb.append("#,");
return;
}
sb.append(root.val + ",");
dfs(root.left, sb);
dfs(root.right, sb);
}
// Decodes your encoded data to tree.
public TreeNode deserialize(String data) {
int[] ret = new int[1];
ret[0] = 0;
TreeNode root = getNode(data, ret);
return root;
}
private TreeNode getNode(String data, int[] idx) {
int n = 0;
int sign = 1;
TreeNode node = null;
while (idx[0] < data.length()) {
char c = data.charAt(idx[0]);
if (c >= '0' && c <= '9') {
n = n * 10 + c - '0';
idx[0]++;
continue;
} else if (c == '-') {
sign = -1;
idx[0]++;
continue;
}
if (c == ',') {
node = new TreeNode(n * sign);
idx[0]++;
node.left = getNode(data, idx);
node.right = getNode(data, idx);
} else {
idx[0]+= 2;
}
break;
}
return node;
}
}
// Your Codec object will be instantiated and called as such:
// Codec codec = new Codec();
// codec.deserialize(codec.serialize(root));这里用深度优先来序列化与反序列化,效率更高,发现耗时0ms的代码是一个做弊的解法,也写一下
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
public class Codec {
private TreeNode root;
// Encodes a tree to a single string.
public String serialize(TreeNode root) {
this.root =root;
return null;
}
// Decodes your encoded data to tree.
public TreeNode deserialize(String data) {
return root;
}
}
// Your Codec object will be instantiated and called as such:
// Codec codec = new Codec();
// codec.deserialize(codec.serialize(root));根本不序列化,反序列化时直接返回root值
亲爱的读者:有时间可以点赞评论一下
作者其它文章



- 数字图像处理
- 剑指offer2
- 工作学习
- 这些算法有自己的方法
- 插件
- 软件使用
- 数学
- mybatis
- 计算机网络
- 正则表达式专栏
- 问题记录
- Thymeleaf
- zuul
- hystrix
- 正则表达式
- feign
- 编程相关技术
- ribbon
- 微服务
- eureka
- 分布式
- 模板
- angularjs
- javascript
- html
- c++ grammar
- c grammar
- python grammar
- java grammar
- 软件工程
- 数据库系统概论
- 转载
- 小知识
- 考研
- webservice
- 网络
- struts2
- springmvc
- springboot
- redis
- mongodb
- hibernate
- 计算机组成原理
- 当代世界经济与政治
- leetcode
- 思想道德修养与法律基础
- 毛泽东思想和中国特色社会主义理论体系概论
- 作乐
- 生活点滴
- 娱乐
- 中国近现代史纲要
- 操作系统
- sunny day, singing day
- 设计模式与算法
- 框架
- 概率论与数理统计
- 线性代数
- JAVA
- 前端
- 数据库
- 马克思主义基本原理概论
- 软考
- 生活,生,活
- 晴雨
- CSS
- LINUX
- java web整合开发王者归来
- 英语
- 高等数学
- 数据结构















全部评论