leetcode探索之链表学习 小结
作者:whisper
链接:http://proprogrammar.com:443/article/249
声明:请尊重原作者的劳动,如需转载请注明出处
在前面的章节中,我们已经学习了许多关于单链表和双链表的知识。
本章节中,我们将总结此前学到的知识,并对链表和其他数据结构进行简短比较。
我们还提供了一些习题,供你练习更多关于链表的内容。
小结 - 链表
复习
让我们简要回顾一下单链表和双链表的表现。
它们在许多操作中是相似的。
- 它们都无法在常量时间内随机访问数据。
- 它们都能够在 O(1) 时间内在给定结点之后或列表开头添加一个新结点。
- 它们都能够在 O(1) 时间内删除第一个结点。
但是删除给定结点(包括最后一个结点)时略有不同。
- 在单链表中,它无法获取给定结点的前一个结点,因此在删除给定结点之前我们必须花费 O(N) 时间来找出前一结点。
- 在双链表中,这会更容易,因为我们可以使用“prev”引用字段获取前一个结点。因此我们可以在 O(1) 时间内删除给定结点。
对照
这里我们提供链表和其他数据结构(包括数组,队列和栈)之间时间复杂度的比较:
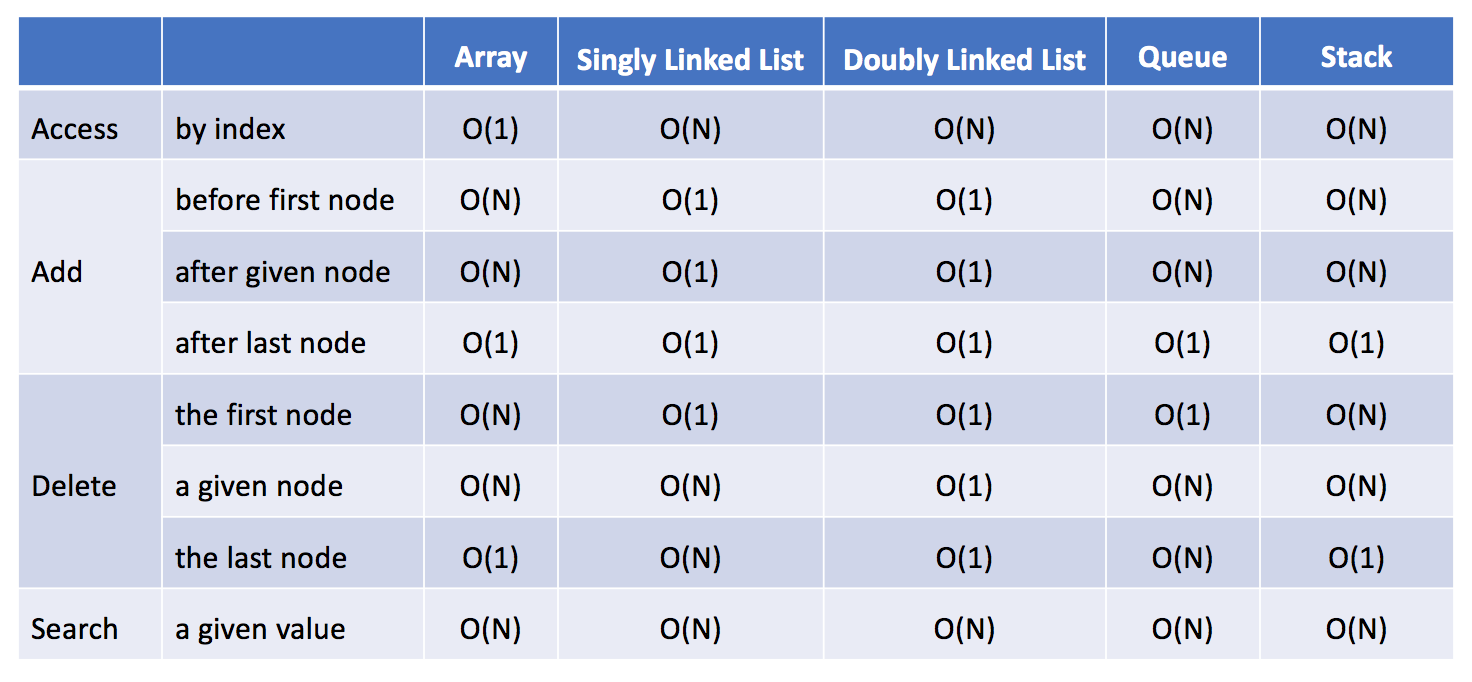
经过这次比较,我们不难得出结论:
如果你需要经常添加或删除结点,链表可能是一个不错的选择。
如果你需要经常按索引访问元素,数组可能是比链表更好的选择。
算法说明
合并两个有序链表
将两个有序链表合并为一个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例:
输入:1->2->4, 1->3->4 输出:1->1->2->3->4->4
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
// 想法:类似于两个有序数组的合并
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
ListNode head = null;
ListNode tail = null;
ListNode tempNode = null;
if(l1 == null){
return l2;
}
if(l2 == null){
return l1;
}
int temp;
while(l1 != null && l2 != null){
if(l1.val > l2.val){
tempNode = new ListNode(l2.val);
if(head == null){
tail = tempNode;
head = tail;
}else{
tail.next = tempNode;
tail = tempNode;
}
l2 = l2.next;
}else{
tempNode = new ListNode(l1.val);
if(head == null){
tail = tempNode;
head = tail;
}else{
tail.next = tempNode;
tail = tempNode;
}
l1 = l1.next;
}
}
while(l1 != null){
tempNode = new ListNode(l1.val);
tail.next = tempNode;
tail = tempNode;
l1 = l1.next;
}
while(l2 != null){
tempNode = new ListNode(l2.val);
tail.next = tempNode;
tail = tempNode;
l2 = l2.next;
}
return head;
}
}定义了一个新链表作为合并后的链表,操作类似两个有序数组的合并,即取出两个链表中较小的拼到新链表中,然后移动到下一个元素,最后要注意的是如果一个链表空了,最后要把另一个还未空链表的剩余元素拼到新链表中,再看一种更好的处理方法
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
if(l1 == null) return l2;
else if(l2 == null) return l1;
if(l1.val <= l2.val){
l1.next = mergeTwoLists(l1.next,l2);
return l1;
}
else{
l2.next = mergeTwoLists(l1,l2.next);
return l2;
}
}
}这里用了递归,没有用辅助空间,代码简洁高效
两数相加
给出两个 非空 的链表用来表示两个非负的整数。其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字。
如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的和。
您可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例:
输入:(2 -> 4 -> 3) + (5 -> 6 -> 4) 输出:7 -> 0 -> 8 原因:342 + 465 = 807
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
ListNode l1c = l1;
ListNode l2c = l2;
ListNode result = null;
ListNode rc = null;
BaseAdd add = new BaseAdd(0, 0);
while(l1c != null && l2c != null)
{
add = new BaseAdd(l1c.val, l2c.val + add.next);
if(result == null)
{
result = new ListNode(add.current);
rc = result;
}
else
{
rc.next = new ListNode(add.current);
rc = rc.next;
}
l1c = l1c.next;
l2c = l2c.next;
}
while(l1c != null)
{
add = new BaseAdd(l1c.val, add.next);
rc.next = new ListNode(add.current);
rc = rc.next;
l1c = l1c.next;
}
while(l2c != null)
{
add = new BaseAdd(l2c.val, add.next);
rc.next = new ListNode(add.current);
rc = rc.next;
l2c = l2c.next;
}
if(add.next != 0)
{
rc.next = new ListNode(add.next);
}
return result;
}
class BaseAdd
{
int current;
int next;
public BaseAdd(int first, int second)
{
current = (first + second) % 10;
next = (first + second) / 10;
}
}
}这里专门定义了一个类BaseAdd来处理带进位的加法,用current表征相加后的当前位,next表征相加后的进位,当前位作为结果链表当前元素的值,进位加到结果链表下个元素的值中,这样比较符合一般思维,但效率会受到影响,下面来看一种更好的方法
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
ListNode head = new ListNode(0);
ListNode result = head;
int temp = 0;
while (l1 != null || l2 != null) {
int val1 = l1 == null ? 0 : l1.val;
int val2 = l2 == null ? 0 : l2.val;
int val = val1 + val2 + temp;
temp = val / 10;
val = val % 10;
result.next = new ListNode(val);
result = result.next;
if (l1 != null) l1 = l1.next;
if (l2 != null) l2 = l2.next;
}
if (temp > 0) {
result.next = new ListNode(temp);
}
return head.next;
}代简洁简,核心思想都是相同的,即每一位的值来源于两数之和加上进位,还可能产生进位,但上面的代码有几个小技巧,当两个链表有一个为空时,继续进行循环,只是令从该链表中取出的值的0,还有一个就是结果链表有一个不存储有效元素的头指针,这样就避免了在循环中判断结果链表是不是空。
扁平化多级双向链表
您将获得一个双向链表,除了下一个和前一个指针之外,它还有一个子指针,可能指向单独的双向链表。这些子列表可能有一个或多个自己的子项,依此类推,生成多级数据结构,如下面的示例所示。
扁平化列表,使所有结点出现在单级双链表中。您将获得列表第一级的头部。
示例:
输入: 1---2---3---4---5---6--NULL | 7---8---9---10--NULL | 11--12--NULL 输出: 1-2-3-7-8-11-12-9-10-4-5-6-NULL以上示例的说明:
给出以下多级双向链表:
我们应该返回如下所示的扁平双向链表:


/*
// Definition for a Node.
class Node {
public int val;
public Node prev;
public Node next;
public Node child;
public Node() {}
public Node(int _val,Node _prev,Node _next,Node _child) {
val = _val;
prev = _prev;
next = _next;
child = _child;
}
};
*/
class Solution {
// 想法:利用递归
public Node flatten(Node head) {
Node temp = head, subTemp, flatTemp;
while(temp != null){
if(temp.child != null){
subTemp = temp.next;
flatTemp = flatten(temp.child);
flatTemp.prev = temp;
temp.next = flatTemp;
temp.child = null;
while(temp != null && temp.next != null){
temp = temp.next;
}
if(subTemp != null){
temp.next = subTemp;
subTemp.prev = temp;
}
}
temp = temp.next;
}
return head;
}
}利用递归,三个变量,temp用来不断向后遍历,subTemp指向temp后一个元素,flatTemp指向temp的child扁平化的结果,具体的操作是当temp的child不为空时,递归调用方法并将结果赋给flatTemp,然后在temp和subTemp之间插入temp的child扁平化处理后的结果链表flatTemp,下面来看下另一种作法
/*
// Definition for a Node.
class Node {
public int val;
public Node prev;
public Node next;
public Node child;
public Node() {}
public Node(int _val,Node _prev,Node _next,Node _child) {
val = _val;
prev = _prev;
next = _next;
child = _child;
}
};
*/
class Solution {
public Node flatten(Node head) {
if (head == null) {
return null;
}
dfs(head);
head.prev = null;
return head;
}
/**
* 展开链表,展开后链表的头结点的 prev 指向尾结点
*
* @param head 头结点
* @return 展开后链表的头结点
*/
private Node dfs(Node head) {
Node cur = head;
while (cur != null) {
head.prev = cur; // 更改头结点的 prev 指向尾结点
Node next = cur.next;
if (cur.child != null) {
Node h = dfs(cur.child);
cur.child = null;
Node t = h.prev;
// 链接 cur、h、t、next
cur.next = h;
h.prev = cur;
t.next = next;
if (next != null) {
next.prev = t;
}
head.prev = t; // 更改头结点的 prev 指向尾结点
}
cur = next;
}
return head;
}
}基本的思路都类似,优点是这里利用了head的prev这个多余的指针来存储扁平化子链表的最后一个元素,省去了从头找最后一个元素的一个循环,所以效率非常高
复制带随机指针的链表
给定一个链表,每个节点包含一个额外增加的随机指针,该指针可以指向链表中的任何节点或空节点。
要求返回这个链表的深拷贝。
示例:
输入:{"$id":"1","next":{"$id":"2","next":null,"random":{"$ref":"2"},"val":2},"random":{"$ref":"2"},"val":1} 解释: 节点 1 的值是 1,它的下一个指针和随机指针都指向节点 2 。 节点 2 的值是 2,它的下一个指针指向 null,随机指针指向它自己。提示:
1. 你必须返回给定头的拷贝作为对克隆列表的引用。

/*
// Definition for a Node.
class Node {
public int val;
public Node next;
public Node random;
public Node() {}
public Node(int _val,Node _next,Node _random) {
val = _val;
next = _next;
random = _random;
}
};
*/
class Solution {
// 想法:随机指针最后特殊处理
public Node copyRandomList(Node head) {
Node newHead, temp, temp2, temp3;
Map<Integer, Node> nodes = new HashMap<>();
int tempVal;
if(head == null){
return null;
}
temp = head;
temp2 = new Node(head.val, null, null);
newHead = temp2;
nodes.put(temp2.val, temp2);
temp = temp.next;
while(temp != null){
temp3 = new Node(temp.val, null, null);
nodes.put(temp3.val, temp3);
temp2.next = temp3;
temp2 = temp2.next;
temp = temp.next;
}
temp = head;
temp2 = newHead;
while(temp != null){
if(temp.random != null){
tempVal = temp.random.val;
temp2.random = nodes.get(tempVal);
}
temp = temp.next;
temp2 = temp2.next;
}
return newHead;
}
}算法的思想是先复制一个新链表而不处理random,用map存储新链表的每个节点(与原链表节点对应),新链表建好后新链表和原链表一起平行移动,从map中找出原链表元素的random对应的结点,作为新链表对应元素的random结点,下面看另外的一种算法
/*
// Definition for a Node.
class Node {
public int val;
public Node next;
public Node random;
public Node() {}
public Node(int _val,Node _next,Node _random) {
val = _val;
next = _next;
random = _random;
}
};
*/
class Solution {
public Node copyRandomList(Node head) {
// if (head == null) {
// return null;
// }
Node curr = null;
Node next = null;
Node copy = null;
curr = head;
while (curr != null) {
next = curr.next;
copy = new Node();
copy.val = curr.val;
curr.next = copy;
copy.next = next;
curr = next;
}
curr = head;
while (curr != null) {
if (curr.random != null) {
curr.next.random = curr.random.next;
}
curr = curr.next.next;
}
curr = head;
Node header = new Node();
Node copyCurr = header;
while (curr != null) {
copyCurr.next = curr.next;
copyCurr = copyCurr.next;
curr.next = copyCurr.next;
curr = curr.next;
}
return header.next;
}
}这里的处理就比较巧妙了,首先在原链表的每个元素后复制一个和链表元素相同的元素作为新链表的元素,所以新链表元素(原链表中元素的复制)的random就是它前一个元素(原链表中的元素)的random的后一个元素(对前一个元素的复制),最后将原链表中的原链表元素和复制的新链表元素进行分离,形成两个链表,返回新链表的头节点
旋转链表
给定一个链表,旋转链表,将链表每个节点向右移动 k 个位置,其中 k 是非负数。
示例 1:
输入: 1->2->3->4->5->NULL, k = 2 输出: 4->5->1->2->3->NULL 解释: 向右旋转 1 步: 5->1->2->3->4->NULL 向右旋转 2 步: 4->5->1->2->3->NULL示例 2:
输入: 0->1->2->NULL, k = 4 输出: 2->0->1->NULL 解释: 向右旋转 1 步: 2->0->1->NULL 向右旋转 2 步: 1->2->0->NULL 向右旋转 3 步: 0->1->2->NULL 向右旋转 4 步: 2->0->1->NULL
// 想法:先找出链表长度,截后若干位,放到头部
public ListNode rotateRight(ListNode head, int k) {
if(head == null){
return null;
}
int len = 0;
ListNode temp, pre;
temp = head;
while(temp != null){
len++;
temp = temp.next;
}
k %= len;
if(k == 0){
return head;
}
pre = head;
for(int i = 1; i < len - k; i++){
pre = pre.next;
}
temp = pre.next;
pre.next = null;
pre = head;
head = temp;
while(temp != null && temp.next != null){
temp = temp.next;
}
temp.next = pre;
return head;
}先计算出链表的长度,截取后k位,放到头部,这样会两次遍历链表,所以效率不是很好,想到的一种更好的方式是用两个指向当前元素前一个元素的指针,开始时都指向头结点,一个指针先移动k次到达一个位置,然后两个指针再一起移动,当第一个指针的next为空时,第二个指针刚好在倒数第k个元素前一个位置,这样就找到了最后k个元素,这样两次循环其实只遍历了一遍链表即可以完成对链表的旋转。想法来自删除链表的倒数第N个节点这道题,该题在leetcode探索之链表学习 双指针技巧有介绍。
亲爱的读者:有时间可以点赞评论一下
作者其它文章



- 数字图像处理
- 剑指offer2
- 工作学习
- 这些算法有自己的方法
- 插件
- 软件使用
- 数学
- mybatis
- 计算机网络
- 正则表达式专栏
- 问题记录
- Thymeleaf
- zuul
- hystrix
- 正则表达式
- feign
- 编程相关技术
- ribbon
- 微服务
- eureka
- 分布式
- 模板
- angularjs
- javascript
- html
- c++ grammar
- c grammar
- python grammar
- java grammar
- 软件工程
- 数据库系统概论
- 转载
- 小知识
- 考研
- webservice
- 网络
- struts2
- springmvc
- springboot
- redis
- mongodb
- hibernate
- 计算机组成原理
- 当代世界经济与政治
- leetcode
- 思想道德修养与法律基础
- 毛泽东思想和中国特色社会主义理论体系概论
- 作乐
- 生活点滴
- 娱乐
- 中国近现代史纲要
- 操作系统
- sunny day, singing day
- 设计模式与算法
- 框架
- 概率论与数理统计
- 线性代数
- JAVA
- 前端
- 数据库
- 马克思主义基本原理概论
- 软考
- 生活,生,活
- 晴雨
- CSS
- LINUX
- java web整合开发王者归来
- 英语
- 高等数学
- 数据结构















全部评论